Python task queue latency
Python’s task queue libraries differ greatly in how long it takes to get a result back.
Most of this variation in latency comes from two design decisions:
- Whether to use polling (slow) or signals/blocking (fast) to communicate with workers.
- How much acknowledgements, heartbeats, backoff and retrying to do. These features add reliability, but also add latency due to additional round trips.
For GPXZ I sometimes need to wait for task results in the context of an HTTP API request. In this case, latency is very important as there’s a user waiting for the result on the other end! Similarly I don’t care about graceful failover or preventing double-calculation or retires: if the task times-out or fails I’ll just fail the API request. Any recovery will be too late.
So I wanted to know which of the Python task queue libraries would be best for this usecase.
Source code
The source code for this benchmark is here: gpxz/queue-latency-benchmark.
Results
- If every nanosecond counts, consider using redis blocking operations directly. In theory, you can get latency down to one RTT along your
client -> redis -> worker. - Otherwise, dramatiq+rabbitmq isn’t much slower than the theoretical limit.
- Celery+redis is a good option if you’re already using redis.
Candidates
I tried the most popular libraries:
- rq v1.15.0
- huey v2.4.5
- dramatiq v1.14.2 with both redis v7.0.11 and rabbitmq v3.12.0 backends
- celery v5.3.0 with both redis v7.0.11 and rabbitmq v3.12.0 backends
rq and huey only support redis for job queues. I ran two instances of dramatiq and celery: one with redis, and a second with rabbitmq v3.12.0.
All candidates used redis as their result backend. Celery is supposed to be able to store results in rabbitmq also, but I couldn’t get that to work.
Reckless queue
In addition to the four mature python packages above, I wrote a quick redis task queue optimised for maximum speed. This isn’t too hard when you don’t care about persistence, acknowledgements, features, stability, or correctness.
class Result:
def __init__(self, job_name):
self.result_key = f'job_result:{self.job_name}'
def block_for_return_value(self):
return redis_client.brpop(self.result_key, timeout=timeout)[1]
def save_return_value(self, return_value):
redis_client.rpush(self.result_key, json.dumps(return_value))
def enqueue(queue_name='default'):
# Prepare job.
job_name = str(uuid.uuid4())
job = {'name': job_name}
# Push job to queue.
redis_client.rpush(f'queue:{queue_name}', json.dumps(job))
return Result(job_name)
def work(queue_name='default'):
while True:
_, encoded_job = redis_client.brpop(f'queue:{queue_name}')
job = json.loads(encoded_job)
# Our worker only does one thing.
return_value = tracked_sleep_task()
result = Result(job['name'])
result.save_return_value(return_value)
if __name__ == "__main__":
work()
Setup
The exact syntax was different for each queue library, but general approach was:
def tracked_sleep_task():
result = {}
result['started_at'] = time.time()
time.sleep(1)
result['ended_at'] = time.time()
return result
enqueued_at = time.time()
job = queue.submit(tracked_sleep_task)
result = job.block_for_result()
returned_at = time.time()
This gives us two different latency values:
latency_enqueue = started_at - enqueued_at: The time between the client submitting the job and the worker starting it.latency_result = returned_at - ended_at: The time between the worker finishing the job and the client getting the result.
I repeated the task loop 100 times for each library. The first result was discarded (to avoid high-latencies due connection establishment and cache population).
Enqueue latency
First the latency between submitting a job and the worker running it.
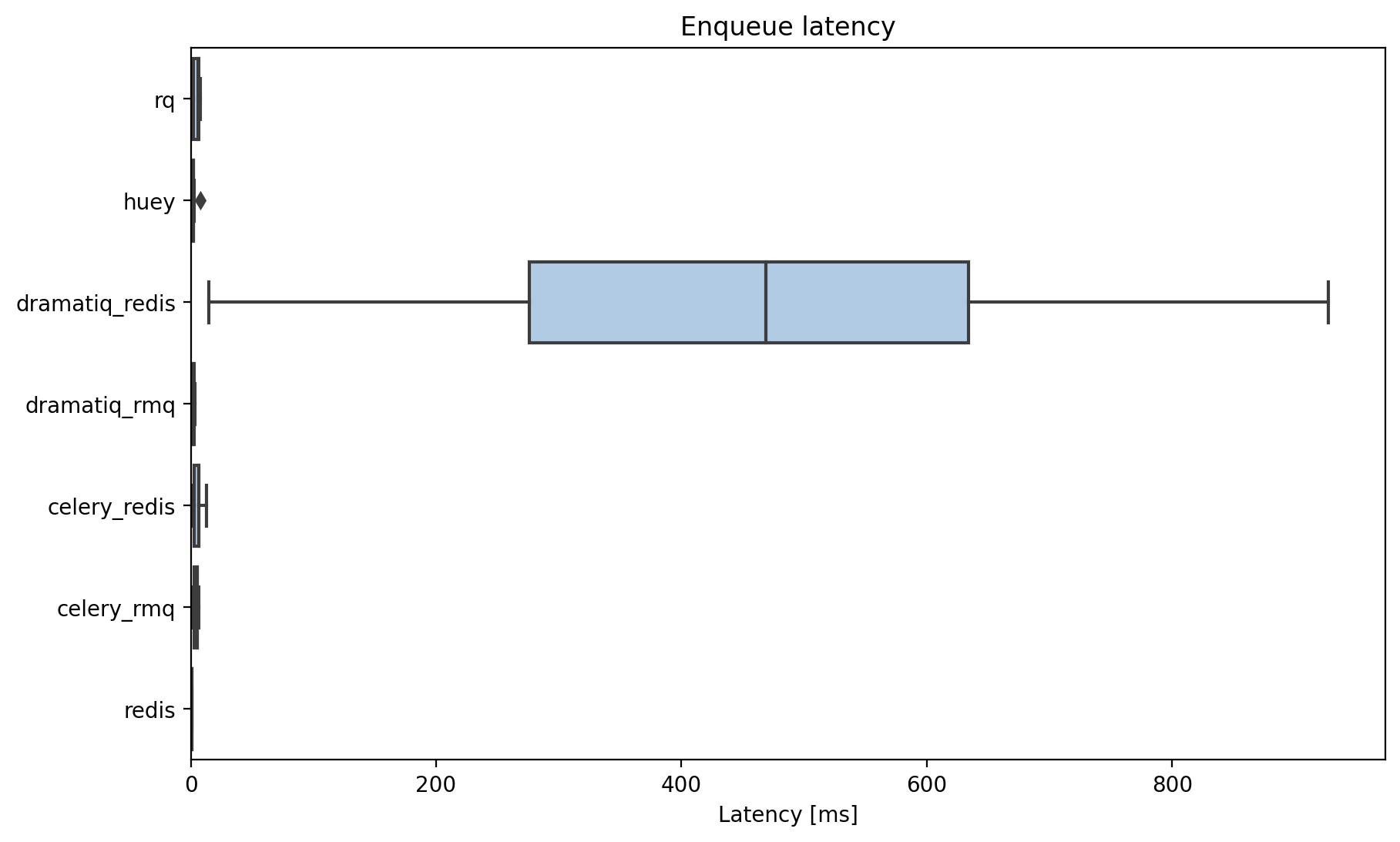 Latency to enqueue a job.
Latency to enqueue a job.
The redis broker in dramatiq has a number of timeouts and sleeps when the queue is idle, and these cause huge latency. These timeouts can’t be easily set with the CLI or the high-level API.
You could subclass or hack the sleeps them if suficiently motivated, but even then, _RedisConsumer uses polling to check for new jobs so there will always be significantly more latency than blocking approaches.
Lets drop dramatiq+redis and have another look at the results:
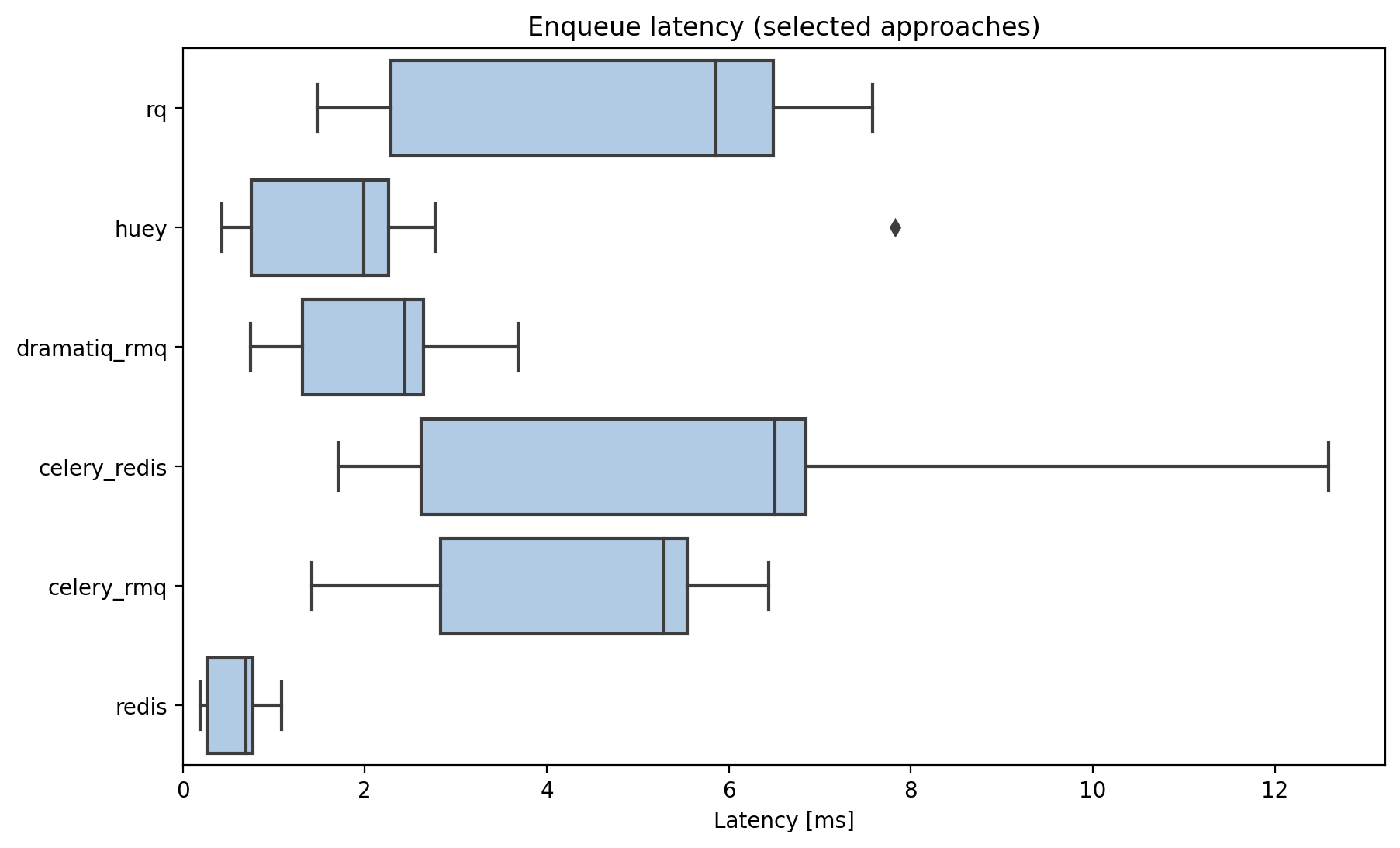 Latency to enqueue a job (fast results only).
Latency to enqueue a job (fast results only).
Huey does well but still can’t beat using raw redis rpush, brpop commands.
Result latency
This is the time taken to return the result from the worker.
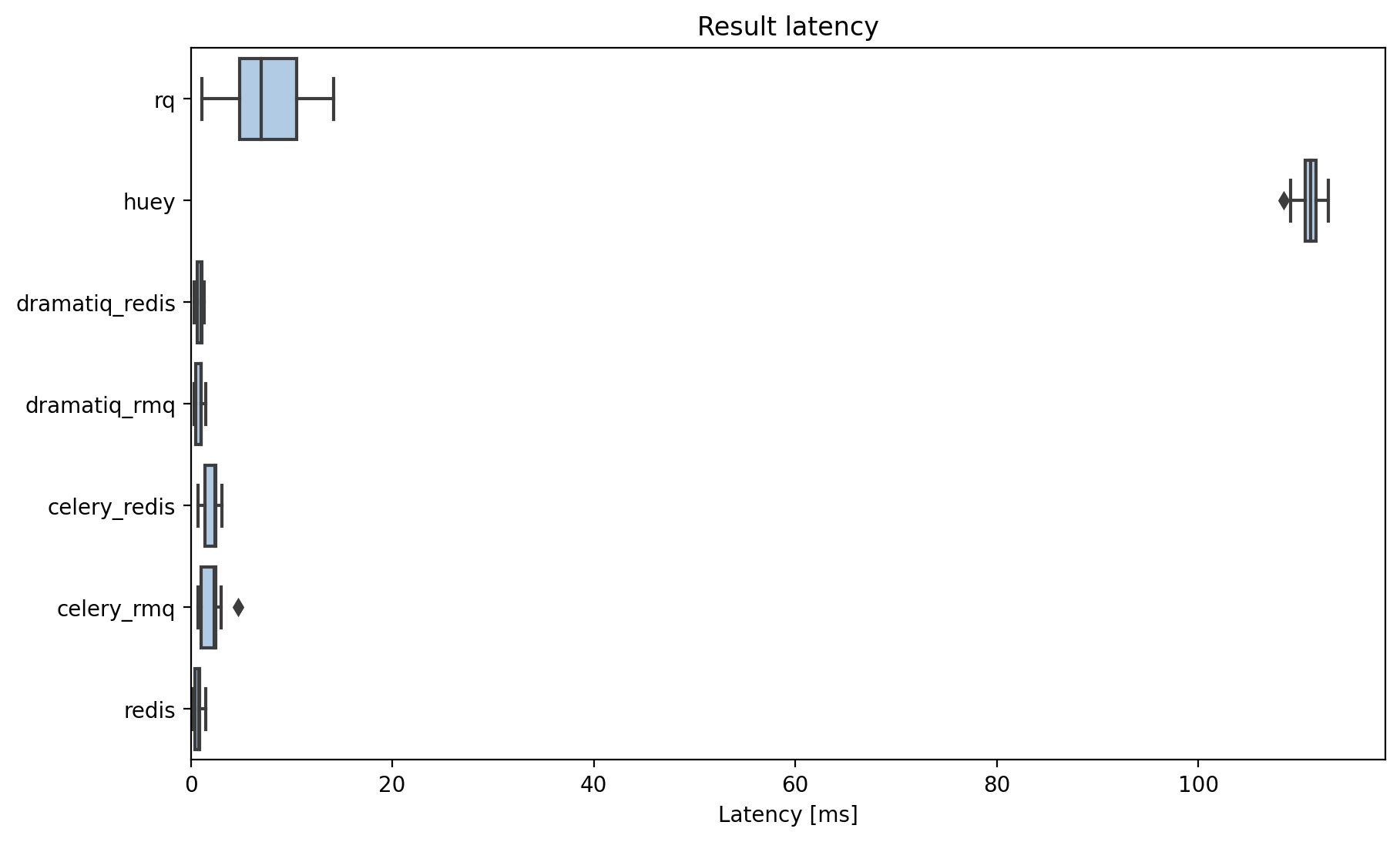 Latency to return a job result.
Latency to return a job result.
Huey struggles here: it does polling on a hardcoded 100ms loop. You can manually poll for results (as I did for rq) which would make the latency similar to rq’s result.
rq doesn’t have an API for blocking results so you have to do your own polling. The result shown above is with 10ms polling: it’s a performance improvement on huey because you can choose your own interval. But to get down to the ~1ms median return time of the other libraries you’ll be thrashing your redis instance.
I made a pull request to remove the need for polling with rq: the results should be much better once that is merged.
Here are the results without rq and huey
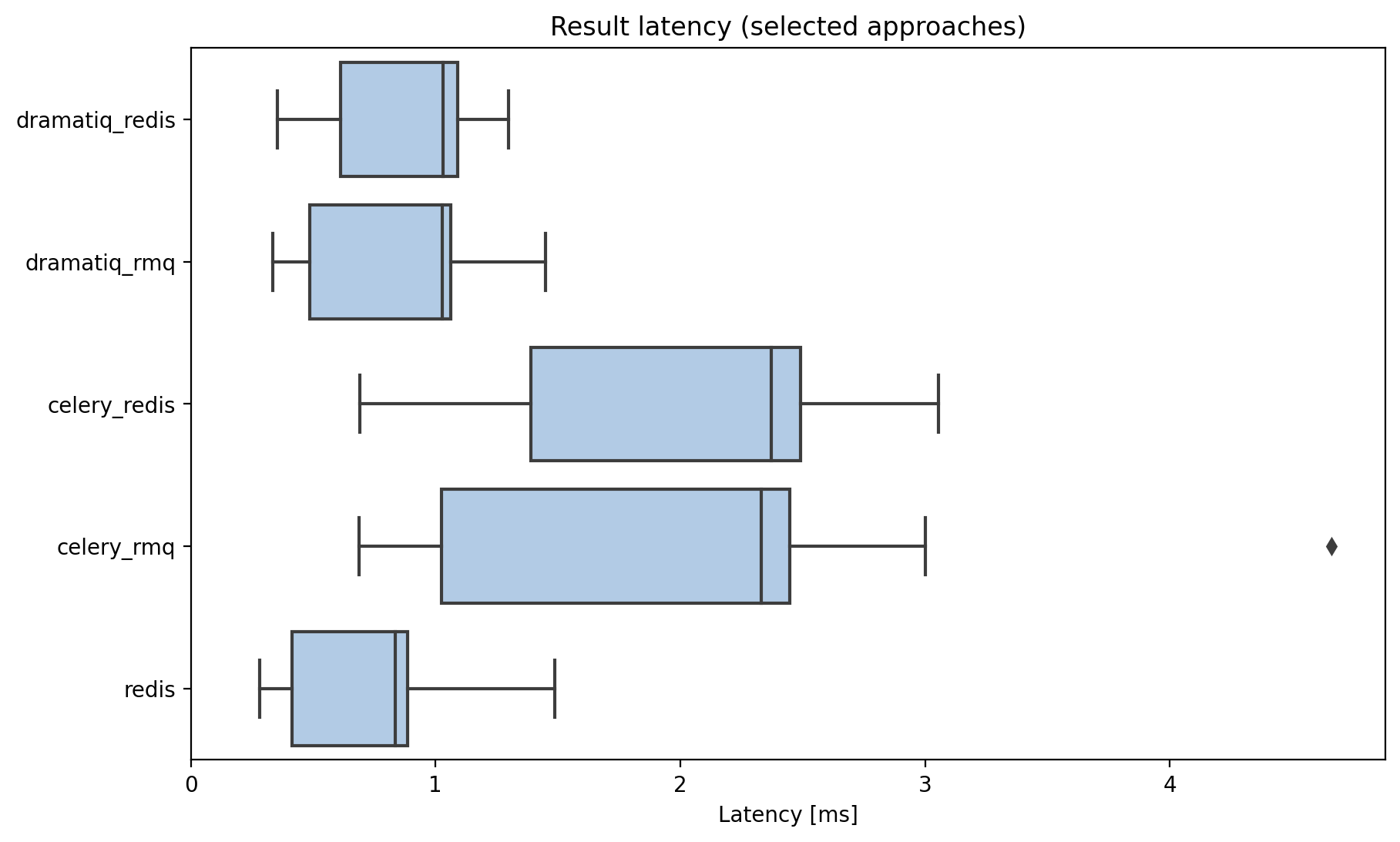 Latency to return a job result.
Latency to return a job result.
There’s no difference here between the _rmq and _redis functions, as all approaches use redis for result serialization, even if the job backend is rabbitmq.
Dramatiq is basically as fast as possible, which is awesome cause you get a lot more with dramatiq compared to my hacky script!
Total latency
Overall: huey, and dramatiq+redis aren’t the best choice for low-latency task queues. Which is a shame as these are the simplest to configure (without relying on celery or rabbitmq)!
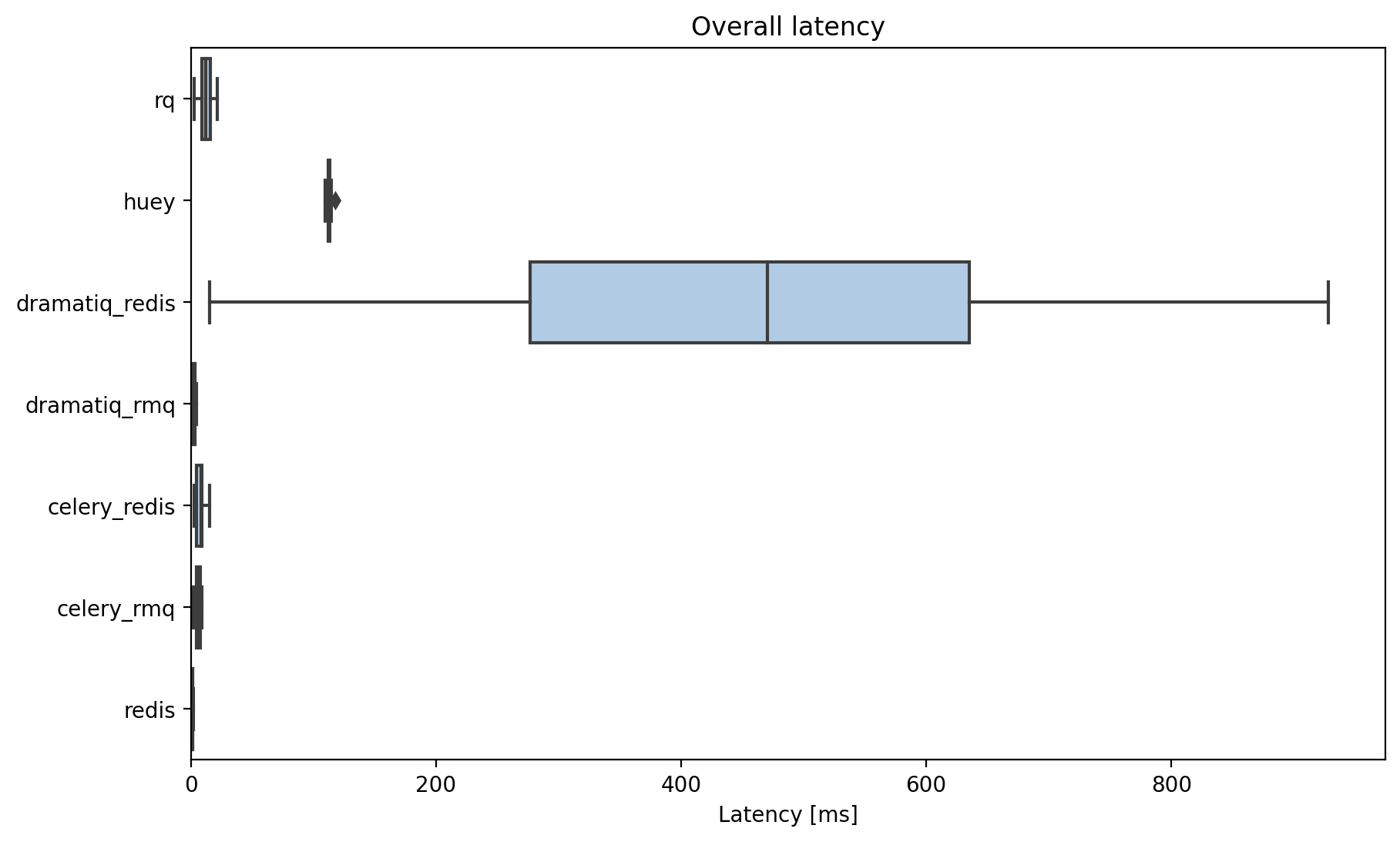 Total latency (not including time spend working)
Total latency (not including time spend working)
Without those libraries there are some decent options:
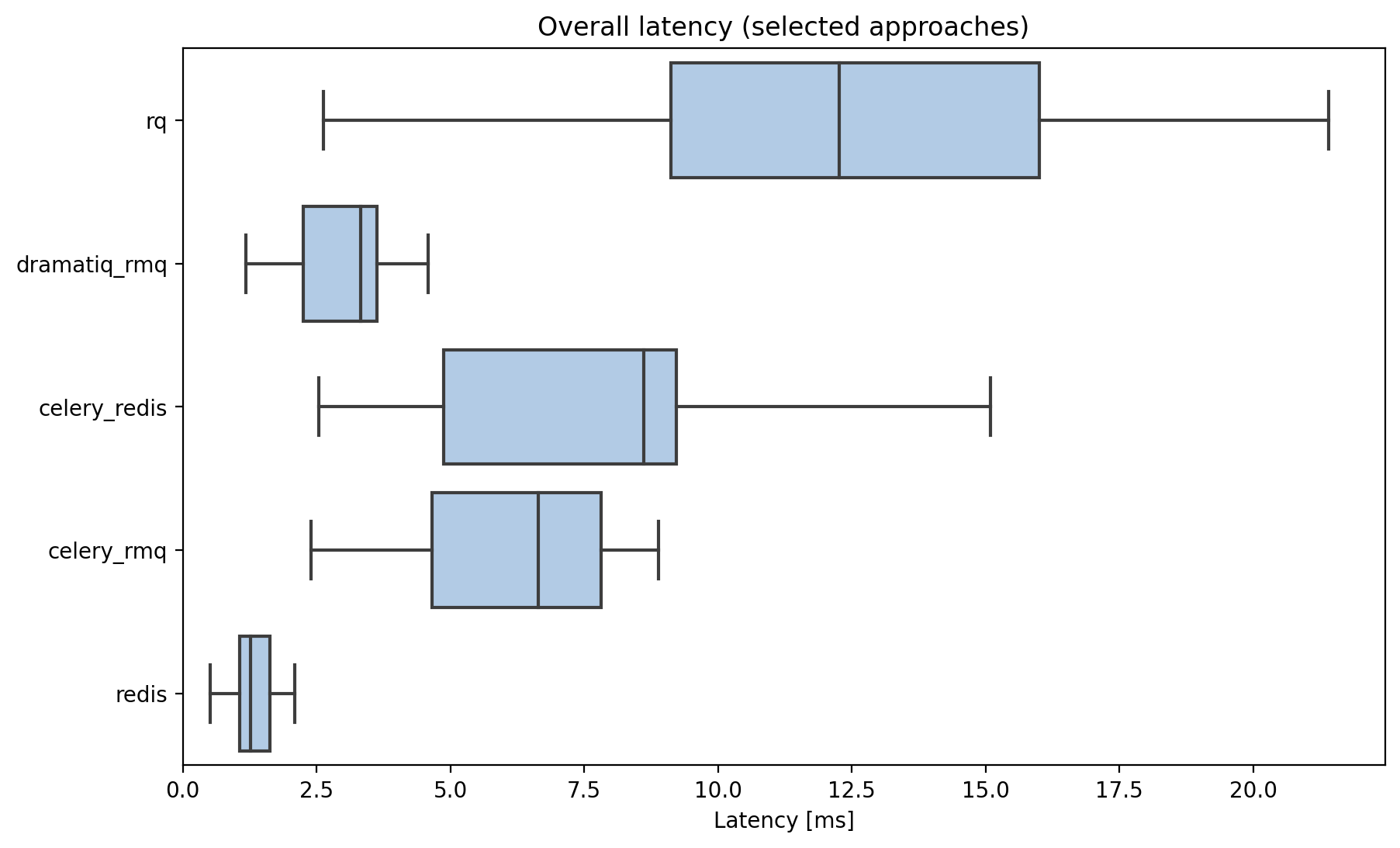 Total latency (not including time spend working)
Total latency (not including time spend working)
rq offers good performance for such a simple deployment experience, and should be a bit faster still once blocking results are released.
Dramatiq+rabbitmq was the fastest off-the-shelf task queue tested. Dramatiq is much easier to work with than celery, but rabbitmq is a pain to set up and run.
If speed is important above all else, consider a DIY approach with redis!